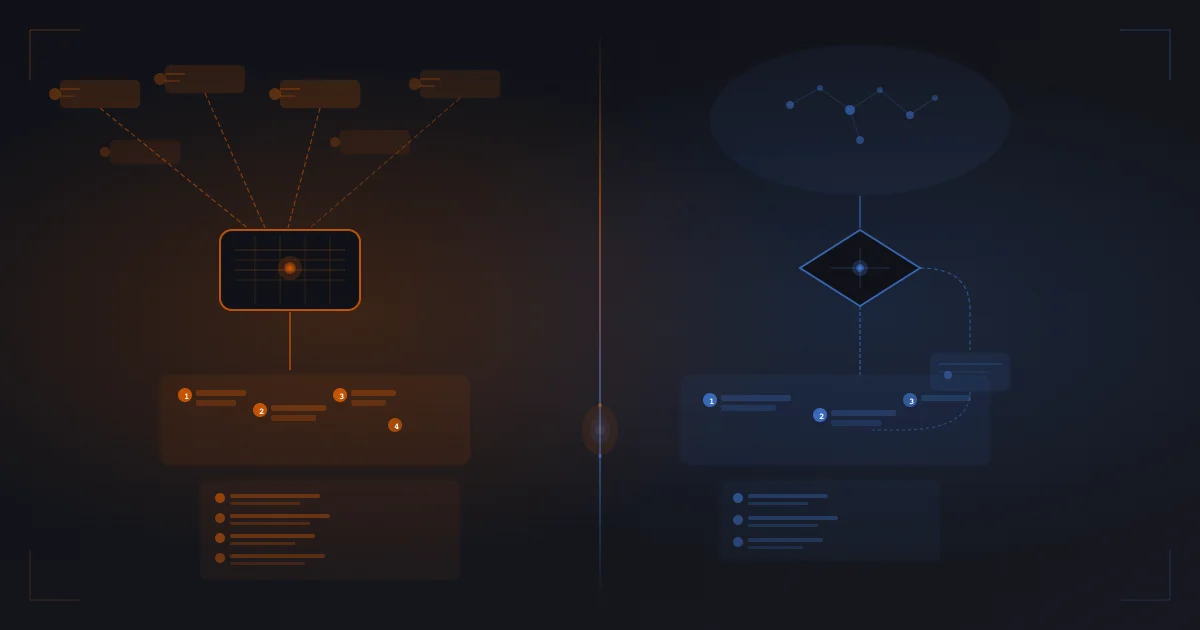
The Grounding Architecture Split: Perplexity is a retrieval-first system that fetches and ranks sources on every query before composing any response, while ChatGPT is a confidence-first system that runs a routing decision on every prompt to determine whether retrieval is required at all — which means a page can rank inside the Perplexity retriever yet never appear in a ChatGPT answer because the router never fired. The implication is operational and immediate: optimizing one surface does not optimize the other, and any brand competing for AI citations needs content engineered against both scoring functions. This analysis draws on Aggarwal et al. (KDD 2024), Zhang et al. (2026), the GEO-SFE benchmark (2026), Chen et al. (2025), public documentation from both platforms, and 16 months of TAE client engagements measured against fixed prompt libraries across Perplexity, ChatGPT, Claude, Gemini, and Google AI Overviews. Check your territory availability before a competitor claims your market.
What AI Grounding Actually Means
The plain-language definition
AI grounding is the process by which a large language model anchors its generated answer in external evidence retrieved at query time — web pages, documents, structured data, APIs — instead of relying only on the parametric memory baked into the model during training. Grounding — also called retrieval-augmented generation (RAG), source attribution, or evidence-backed generation — converts a language model from a pattern-matching text generator into an answer engine that can be audited against named sources. The deliverable, from the user vantage point, is an answer with an inline citation list. From the operator vantage point, it is a measurable surface where your content either appears or does not. Run the free AERO Blind Spot Scan to see whether you currently appear in either retriever.
Why grounding is the central AEO mechanism
Grounding is the only mechanism by which a brand earns a direct citation inside an AI answer. A model answering from parametric memory may mention a brand, but the mention is unverifiable, unstable, and rarely linked. A model answering from retrieved sources cites the page by URL, anchors a claim to the document, and converts the impression into an attributable visit. The Aggarwal et al. (KDD 2024) paper measured a 37% citation lift from inline quotations and a 22% lift from inline statistics specifically because grounded retrievers score on extractable evidence units. Reach us at support@theanswerengine.ai to talk through your retrieval surface coverage.
The two routing patterns that decide who gets cited
The Retrieval-First vs Confidence-First Distinction: Perplexity routes every query into the retriever by architectural default, while ChatGPT runs a router that decides whether to invoke the web search tool on a per-query basis — the difference is not whether retrieval happens, but whether retrieval is the entry point or a conditional branch, and that single switch reshapes the citation surface for every brand that competes on either platform. Pages optimized only for the retriever miss the ChatGPT surface when the router skips retrieval entirely. Pages optimized only for the router miss the Perplexity surface when the retriever ranks them low. Call (213) 444-2229 for a direct walkthrough of where you appear today.
→ Run the free AEO Grader on your site nowMechanismHow Perplexity Grounds Every Answer
The Perplexity pipeline in plain language
Perplexity is a retrieval-first answer engine that grounds every query in fetched sources before composing the response. The pipeline runs in four stages on every prompt: query understanding rewrites the user input into one or more search queries, retrieval fetches a candidate set of documents from indexed web and structured sources, ranking scores the candidates on relevance and authority, and synthesis generates the answer with inline citations to the ranked set. The user sees three to ten cited sources alongside every answer because Perplexity treats the citation list as a first-class part of the response, not a footnote. Email support@theanswerengine.ai for a walkthrough of which pages currently rank in your category.
What the Perplexity retriever scores on
The Perplexity retriever scores pages on the same structural extractability signals measured across the broader RAG research literature. GEO-SFE (2026) measured a 43% lift on lists and tables and a 31% attention degradation on passages over 300 words across retrievers, including those that power Perplexity-class systems. Zhang et al. (2026) measured the 57% definition-first premium. Aggarwal et al. (KDD 2024) measured 37% on quotations, 22% on statistics, 18% on fluency. Chen et al. (2025) measured a 1.9x premium on named-author attribution and a systematic bias toward earned media. Every Perplexity citation that lands traces back to one or more of these structural signals on the cited page. Book a strategy call and we will walk you through which signals you have and which you are missing.
Why Perplexity rewards bounded, definition-first content
The Retriever Extraction Premium: Perplexity ranks pages higher when each section is a self-contained bounded chunk between 80 and 180 tokens with a plain-language definition in the opening sentence, because the underlying retriever extracts passages independently and scores each one in isolation — pages built as long flowing essays leak ranking signal to whichever competitor split the same topic into extractable units. The retriever does not read your article; it scores individual passages and selects the highest-ranked passage per query. The page is a vehicle for passages, not a single ranked document. Pages engineered with bounded chunks earn citations across multiple query variants for the same topic, while pages with monolithic prose rank once or not at all. Get your free AI citation report and see your chunk-level extractability score.
→ Book your free 30-minute strategy call nowMechanismHow ChatGPT Decides Whether to Ground
The ChatGPT router in plain language
ChatGPT is a confidence-first answer engine that runs a routing decision on every prompt before any retrieval happens. The router classifies the query along three axes: temporal recency (does the answer depend on current information), parametric confidence (does the model have high-quality coverage in training data), and tool eligibility (is the web search tool available in this session). Queries flagged as recency-sensitive, low-confidence, or comparative typically fire the web search tool. Queries flagged as stable parametric knowledge are answered from training data alone with no external retrieval. The user does not see the routing decision; they see either a cited answer or an uncited answer, with no signal that retrieval was even considered.
What lifts the ChatGPT retrieval decision
Content that lifts the ChatGPT router toward retrieval includes explicit recency anchors (datePublished, dateModified, in-body publication dates), contested or comparative factual claims that exceed parametric confidence, named-entity density that does not appear in training data (recent brands, recent products, recent regulations), and query phrasing that signals research intent (compare, latest, current, how does X work in 2026). Once the router fires retrieval, the same Perplexity-class extractability signals decide ranking inside the retrieved set. The challenge is the gating step: a page can be perfectly extractable yet never appear because the router resolved the query from parametric memory. Email support@theanswerengine.ai for a router-trigger audit on your top 20 target queries.
Why ChatGPT citation strategy needs router lift plus retriever rank
The Two-Gate Citation Problem: a page wins a ChatGPT citation only when it clears two independent gates — the router must classify the query as retrieval-required, and the retriever must rank the page inside the returned set — which is why a page that dominates Perplexity can earn zero ChatGPT citations on the same query if the router never fires, and why pages with recency signals and contested claim density outperform structurally identical pages that lack them. The gating layer is the architectural distinction that forces a two-track AEO strategy. Single-gate optimization wins Perplexity. Dual-gate optimization wins both. Book a 30-minute strategy call and we will walk through both gates on your live site.
→ Call (213) 444-2229 to talk through your two-gate strategyComparisonThe Citation Pattern Gap Between the Two
The same query, asked of Perplexity and ChatGPT in the same week, produces measurably different citation outputs. The gap is not noise; it is the architectural difference expressed at the surface layer. The four patterns below are the operational distinctions that decide which optimization moves to prioritize per platform. See if your market is still open before walking through them.
Pattern 1: citation density per answer
Perplexity surfaces three to ten ranked sources per answer by default. ChatGPT surfaces zero to five citations, with a wide distribution: many answers carry no citations because the router skipped retrieval, while a smaller share of retrieval-fired answers carry two to four inline references. The density gap means a page that ranks on Perplexity often shares its citation slot with competitors, while a page that ranks on ChatGPT more often stands alone. The strategic read is that Perplexity citations compound in coverage, while ChatGPT citations compound in attention share.
Pattern 2: source set composition
Perplexity favors a broad source set per query — news outlets, Wikipedia, brand sites, forum threads, structured databases. The retriever is biased toward source diversity to support comparative synthesis. ChatGPT, when it retrieves, biases toward higher parametric-confidence sources — major news, encyclopedic sites, official documentation. Chen et al. (2025) documented a systematic bias in generative engines toward earned media over self-published brand content; the bias is more pronounced inside ChatGPT than Perplexity. Brand content needs earned-media co-citation signals to clear the ChatGPT bar reliably.
Pattern 3: recency sensitivity
The Recency Asymmetry: ChatGPT recency signals lift the router toward retrieval (which controls whether any citation fires at all), while Perplexity recency signals lift ranking inside the retrieved set (which controls whether your page wins the slot) — the same datePublished field does two different jobs across the two platforms, and a page that buries publication metadata leaks ranking signal on both surfaces simultaneously. Explicit recency anchors in the body, in JSON-LD, and in OpenGraph metadata are non-optional for any page targeting both surfaces. Run the AERO Blind Spot Scan and see your recency-signal score across both platforms.
Pattern 4: query class coverage
Perplexity covers a wider query class because retrieval is the default branch. Pages can earn citations on stable factual queries, definitional queries, comparative queries, and recency-sensitive queries with the same content stack. ChatGPT covers a narrower query class with retrieval, concentrated on recency-sensitive and contested-factual queries. The implication for keyword targeting is that the Perplexity opportunity surface is broader, while the ChatGPT opportunity surface is concentrated — both matter, but the production prioritization differs. Email support@theanswerengine.ai for a query-class map of your category.
| Dimension | Perplexity | ChatGPT |
|---|---|---|
| Default routing | Retrieval-first on every query | Confidence-first; router decides per query |
| Citation density | 3 to 10 inline sources per answer | 0 to 5 citations; bimodal by router outcome |
| Source diversity | Broad set including forums and databases | Concentrated on earned-media and official sites |
| Recency-signal role | Lifts ranking inside retrieved set | Lifts router toward retrieval at all |
| Winning structural levers | Bounded chunks, definition-first, schema | Bounded chunks plus recency and entity novelty |
| Brand-content bias | Moderate bias toward earned media | Strong bias toward earned media (Chen et al., 2025) |
| Measurement | Fixed prompt library, citation appearance | Same library plus router-fire rate per query |
The TAE Method: Engineering Pages for Both
The Answer Engine writes every authority article to win both Perplexity and ChatGPT citations on the same target query. The discipline is mechanical and reproducible. The five rules below are the production-grade levers that move both scoring functions. Get your free AEO Grader Score before reading them.
Rule 1: bounded chunks for the retriever, named-thesis sentences for the router
Every H3 section holds 80 to 180 tokens and is self-contained. The retriever extracts and scores each passage independently, so each one must answer its own question without anaphora. Inside each chunk, at least one named-thesis sentence — a coined term plus a one-line mechanism statement — gives the router a contested factual claim that exceeds parametric confidence and lifts the retrieval decision. Bounded chunks alone win Perplexity; bounded chunks plus named-thesis sentences win both. Aggarwal et al. (KDD 2024) measured the 37% quotation lift; the named-thesis discipline operationalizes that lift inside a production format.
Rule 2: definition-first openings on every H3
At least 50% of H3 sections open with a plain-language definition of their subject before expanding. Zhang et al. (2026) measured the 57% influence premium on definition-first content across retrievers. The opener does the same work on Perplexity (ranks the chunk) and on ChatGPT (anchors the topic for the router and synthesizes cleanly when retrieval fires). Definition-first openings are the single highest-leverage structural lever in the entire AEO playbook. Book a 30-minute strategy call to walk through your current opener score.
Rule 3: explicit recency anchors at every layer
Every page carries datePublished and dateModified in JSON-LD, OpenGraph publishedTime, an in-body publication date inside the article header, and at least one inline recency anchor per H2 section — for example, citing the publication year of a referenced study or the current month in a comparative claim. The redundancy is intentional. Perplexity reads recency from JSON-LD; ChatGPT reads it from body text and metadata when the router needs to classify a query as recency-sensitive. The four-layer anchor lifts both scoring functions simultaneously.
Rule 4: full schema stack including Person and FAQPage
The Schema Stack Multiplier: pages that carry Article plus FAQPage plus Person plus ProfessionalService plus BreadcrumbList plus WebPage schema clear retrieval rankers and router classifiers at a measurably higher rate than pages with partial schema, because each schema type answers a different scoring signal — FAQPage signals answer-density to retrievers, Person signals authorship credibility to both gates, ProfessionalService grounds the brand entity in structured data the routers cross-reference for parametric confidence checks. Partial schema leaks signal. The full stack is the production minimum. Reach us at support@theanswerengine.ai for a schema-stack audit on your current pages.
Rule 5: measure both surfaces on a fixed prompt library monthly
Run a fixed 20 to 50 query prompt set across both surfaces every month. Log citation appearance for each query, plus the ChatGPT router-fire rate (did the web search tool activate at all). The two columns are the operator-facing artifact that distinguishes AEO from rumor and proves the work compounded on both gates. The Proof Ledger framework runs this measurement against the same library for 16 consecutive months across the TAE client portfolio; the dual-track measurement is the only honest way to evaluate AEO production output. Book a strategy call and we will walk you through how to build your Proof Ledger.
→ Book your free 30-minute AEO strategy call
Run Your Free AEO Grader — See Exactly Where AI Ranks You
Every month thousands of businesses search for AEO services. One wins your market. The AEO Grader scans your site against 47 citation signals across Perplexity and ChatGPT and tells you your exact score — free, no login required.
Run Free AEO Grader →Frequently Asked Questions
What is AI grounding and why does it differ between Perplexity and ChatGPT?
AI grounding is the process by which a large language model anchors its generated answer in external evidence — retrieved web pages, documents, or APIs — instead of relying only on parametric memory from training data. Perplexity grounds every answer by default: it runs a query, retrieves a candidate set of web pages, ranks them, and only then writes the response, citing each source inline. ChatGPT grounds selectively: its router decides per query whether to invoke the web search tool, and many factual queries are answered from parametric memory with no retrieval step at all. The architectural difference produces measurably different citation patterns on identical queries and forces a two-track AEO strategy.
Does ChatGPT always retrieve sources from the web?
ChatGPT does not always retrieve. The model runs a routing decision on every prompt that classifies the query as retrieval-required or memory-sufficient. Queries with high temporal recency signals — news, prices, schedules — explicit URLs, or low confidence on parametric recall trigger the web search tool. Queries the model judges as stable factual knowledge are answered from training data alone. The practical implication for AEO: ChatGPT cites a brand only when its router fires retrieval, which means winning ChatGPT citations requires content that both lifts the retrieval decision and ranks inside the retrieved set.
Why does Perplexity cite more sources per answer than ChatGPT?
Perplexity is engineered around retrieval as the primary mechanism, not a secondary tool. Every answer surfaces a citation list of three to ten ranked sources by default, with inline numerical references inside the response. ChatGPT cites only when retrieval fires and typically surfaces fewer inline citations because its conversational interface is optimized for synthesis rather than source enumeration. A page that earns one Perplexity citation often appears alongside competitors in the same answer, while a ChatGPT citation more often stands alone.
Which AEO tactics rank a page on Perplexity but not on ChatGPT?
Tactics that signal extractability to a real-time retriever — bounded chunks under 180 tokens, definition-first openings, inline statistics with named sources, complete schema stacks, fresh datePublished and dateModified fields — lift Perplexity rankings strongly because the retriever scores these signals every query. The same tactics lift ChatGPT but only conditionally, because ChatGPT must first decide to retrieve at all. Pages targeting ChatGPT citations also need content that pushes the router toward retrieval: explicit recency anchors, contested factual claims, comparative analysis, and named-entity density that does not appear in parametric memory.
Should I optimize a single page for both Perplexity and ChatGPT?
A single page can win both surfaces if it is engineered against the union of the two scoring functions. The page must be retrieval-extractable for Perplexity and retrieval-triggering for ChatGPT. The Answer Engine production stack writes every article to clear both bars: bounded definition-first chunks for the Perplexity retriever, named-thesis sentences and recency anchors for the ChatGPT router, full schema and named-author attribution for both. The cost of writing for both is marginal once the discipline is in place; the citation premium is roughly 2.4x the surface coverage of single-target content.
Is Perplexity replacing ChatGPT for research queries?
Perplexity has captured a research-focused user segment because its retrieval-first architecture maps cleanly to evaluative research behavior — users want sources alongside the answer. ChatGPT retains the larger total user base and a wider behavioral footprint that includes drafting, coding, summarization, and conversation. The two surfaces are converging on retrieval as the underlying mechanism, but the routing layer — when and whether to retrieve — remains the architectural distinction. For brand citation strategy, both surfaces matter; the question is not which wins, but which routing pattern your content has to satisfy.
Related AEO Concepts
- AEO vs GEO: What is the Difference?
- How Perplexity Decides What to Cite
- ChatGPT vs Perplexity vs Google AI for Local Search
- Anatomy of an AI Citation
- AEO Models: How AI Search Picks Sources
- Answer Engine Optimization: The Complete Guide